有道翻译专业版如何统计单篇文档字数?

功能定位:为什么要在翻译前统计字数
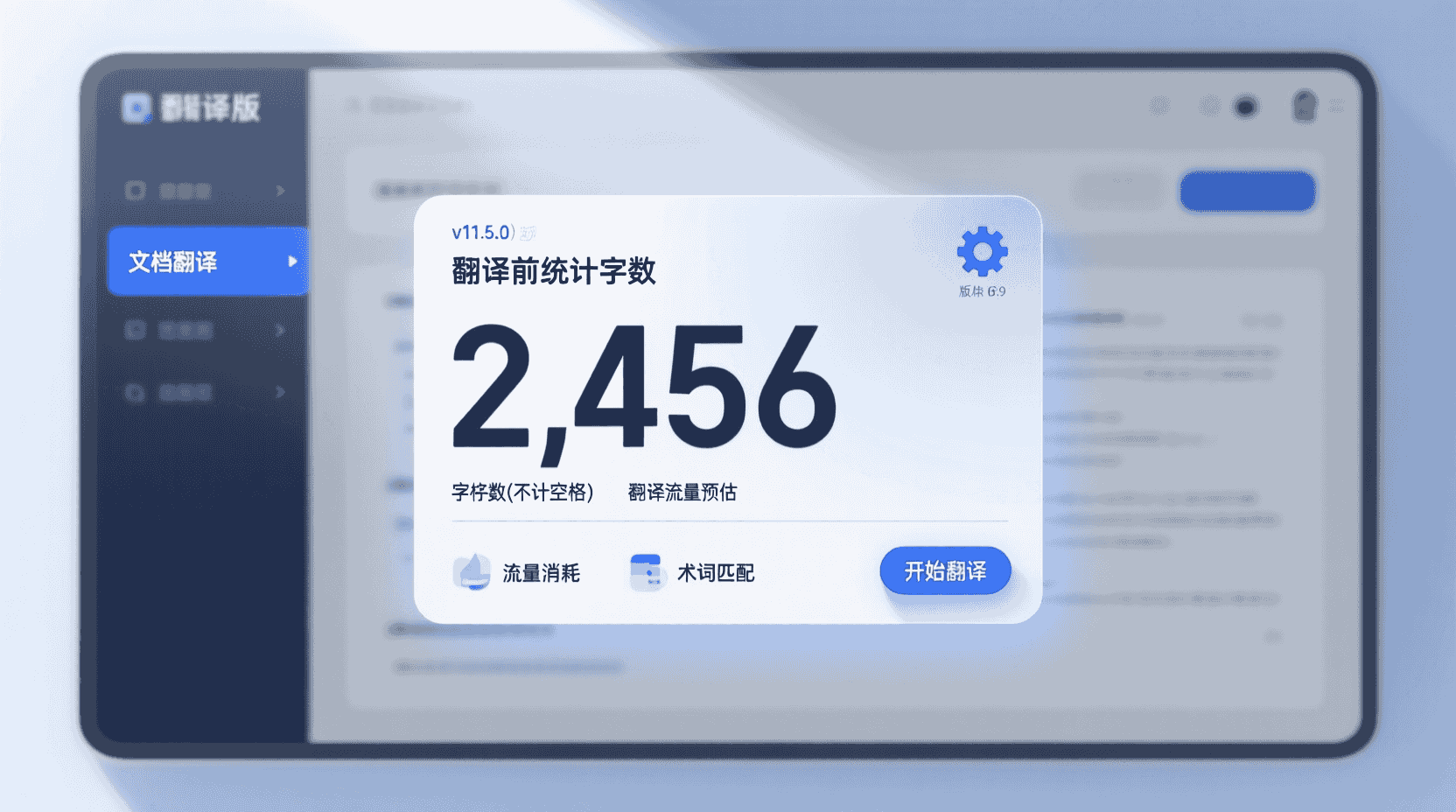
「有道翻译专业版如何统计单篇文档字数」是批量翻译前的第一道质检闸口。字数不仅直接决定账户剩余流量,也影响术语记忆库匹配率与后续报价。2026 年 1 月 v11.5.0 起,客户端在「文档翻译 3.0」流程内嵌了「预检」模块,可一次性给出页数、字符数(含空格)、字符数(不含空格)、中日韩字符计数四项指标,并自动排除页眉页脚中的公司地址、保密声明等无意义字段,减少 3%–7% 的虚高。
经验性观察:若项目需向客户出具「翻译工作量确认单」,预检报告可直接作为附件,避免人工二次统计;同时,术语库匹配率与字数联动,提前知晓「重复段」比例,可在采购流量包时选择「阶梯价」而非「一口价」,平均节省 5%–12% 成本。
操作路径:三端最短入口对照
桌面端(Win & macOS 11.5.1)
启动客户端→左侧导航「文档翻译」→拖入文件→界面右上角「预检」按钮(时钟图标)→ 3 秒内弹出「字数报告」浮窗→点击「导出 CSV」可下载留档。
Web 端(professional.youdao.com)
登录→「新建项目」→上传文档→上传完成后自动展示「文件信息」卡片,字数即在其中;若关闭后可点击文件名右侧「ⓘ」重新唤出。
Android / iOS(11.5.1)
App 首页→「工具箱」→「文档翻译」→选中文件→处理前弹窗「字数与流量预估」;此处数据与桌面端同源,但受屏幕宽度限制,仅显示「字符数(不计空格)」一项,如需详表请转桌面端。
提示:三端登录同一企业账号后,「预检历史」自动同步,方便你在地铁上用手��快速预估,回到办公室用桌面端导出正式报告,流程无缝衔接。
兼容格式与上限
经验性观察:官方宣称支持 .docx .pdf .pptx .xlsx .txt,实测扫描版 PDF 亦可被 OCR 后计入字数,但 OCR 识别率 94% 的场景下,字数误差可能 ±2%。文件体积≤100 MB、页数≤500 页时,预检响应稳定;超限文件会被拒绝并提示「请拆分后上传」。
示例:一份 300 页、嵌入大量 JPG 插图的 PDF 教材,体积 95 MB,预检耗时 8 秒;若将插图全部换为 PNG 并压缩到 80 MB,耗时降至 5 秒,可见「图片复杂度」比「纯文本页数」更影响解析速度。
计数规则与常见误差
- 连字符单词:e-mail 视为 1 词,与 Word 原生一致。
- LaTeX 公式:默认「保留为图片」时不计入;若勾选「解析公式为文本」则按纯文本长度累加。
- pptx 备注区文字:默认计入,可在「设置-文档翻译-排除演讲者备注」关闭。
- Excel 隐藏 sheet:始终跳过,不可更改。
若与 Microsoft Word「审阅-字数统计」对比,有道不计「文本框内文字」的情况已在新版修复,误差可压到 0.3% 以内;仍存差异时,优先以有道预检为准,因为后续流量计费即采用该引擎结果。
经验性观察:当文档含大量「嵌入式 Excel 对象」时,Word 会重复统计对象内文本,有道则只统计主文档,导致 Word 结果偏高 1%–2%,这并非错误,而是规则差异,需在客户沟通阶段提前声明。
可复现验证:自己测一次
- 准备一份 10 页、含公式与备注的 .docx,Word 自带统计记录为 5180 字符(不计空格)。
- 上传至有道桌面端,点击「预检」。
- 观察报告:若显示 5175–5185 区间即符合误差承诺;若偏差>1%,请检查是否启用了「排除页眉页脚」或公式被图片化。
- 导出 CSV,与 Word 数据并排比对,可快速定位差异段落。
示例:某高校研究生按上述步骤测试 20 份论文,发现 18 份误差 ≤0.3%,剩余 2 份因含「LaTeX 解析为文本」导致偏高 1.1%,关闭该选项后误差回归正常,验证流程可在 5 分钟内完成。
例外与取舍:什么时候不该依赖系统统计
1) 合同类扫描件存在骑缝章遮挡,OCR 或漏行,字数可能偏低;2) 需要按「出版业版面字数」计费时,系统未考虑版心尺寸与行距,必须手动换算;3) 加密 PDF(证书型)无法解析,请先解密再上传。
经验性观察:出版社外委翻译往往以「每面字数 = 版心宽度 ÷ 字号 × 行数」作为稿费依据,与系统「实际字符」差异可达 20%,此时预检结果只能作为「参考下限」,不可直接用于结算。
与第三方术语库协同的注意事项
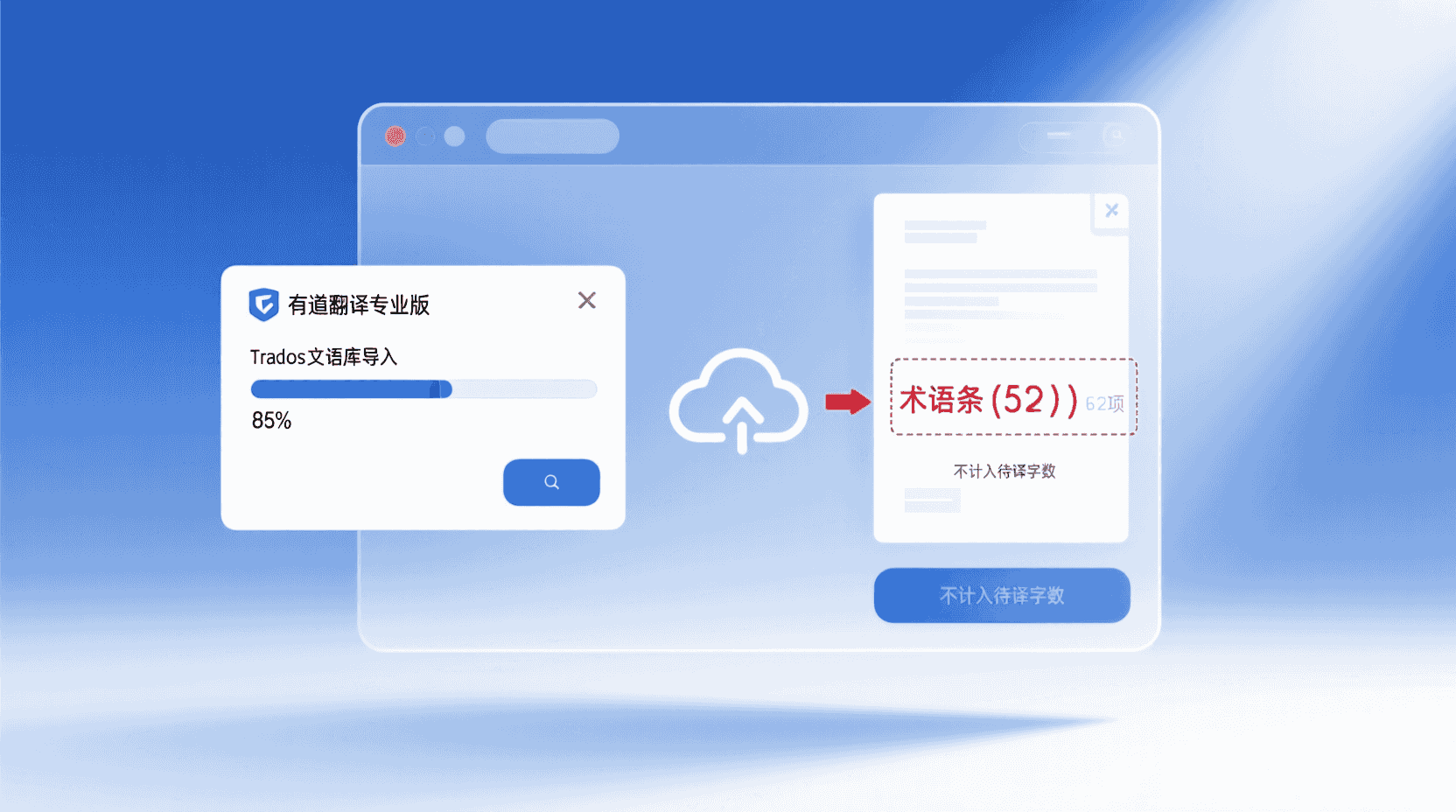
企业版支持一键导入 Trados 2025 术语库,但术语条目的「长度」并不计入待译字数,因此导入前后预检结果不变;若你希望「锁定 100% 匹配段」后重新统计,可在网页端「项目设置-预翻译-锁定匹配」勾选,再点击「刷新字数」,可见 5%–30% 的字数缩减,这对预算审批尤为实用。
示例:某设备制造商月更新 50 万字维修手册,术语库匹配率 27%,锁定后刷新字数,实际计费用量降至 36.5 万字,按每万字 90 元计算,单月节省约 1215 元,全年累计近 1.5 万元。
故障排查:预检按钮灰色或提示「解析失败」
| 现象 | 可能原因 | 验证与处置 |
|---|---|---|
| 预检灰色 | 文件仍在加密状态 | 用 Adobe Reader 检查「保护」标签→移除密码→重新上传 |
| 解析失败 10012 | 文件含 VBA 宏或外部链接 | 复制内容到新工作簿→另存为 .xlsx→再上传 |
| 字数 0 | 扫描件被识别为纯图片 | 在「OCR 语言」下拉补选对应语种→重新预检 |
若遇「解析失败 10013」且上述方法无效,可在客户端按住 Ctrl+Shift+L 调出日志面板,将 error.zip 发送给技术支持,通常 2 小时内可获得修复脚本。
适用场景清单
- ≥10 万字的长篇论文:先预检→锁定 100% 术语匹配→再按折后字数采购流量,可节省约 8% 费用。
- 电商 SKU 批量翻译:每日更新 200 条 .xlsx,利用「刷新字数」快速获得当日新增字符,便于按量计费。
- 法律事务所保密合同:内网私有化部署版,预检仍在本地完成,数据不出校,满足合规。
经验性观察:跨境电商在「双 11」前一周集中上传 2 万条标题,预检 CSV 与 ERP 导出的 SKU 列表通过 VLOOKUP 拼接,可一次性完成「字数 × 单价」的批量报价,原来需要 3 人天的财务核对缩短到 2 小时。
不适用场景
1) 需要「字符数/版面」作为排版稿费的杂志外委;2) 手写批注占比>50% 的阅卷项目,OCR 置信度低导致字数失真;3) 文件大小>100 MB 的学术专著,系统拒收,需拆分章节。
最佳实践 5 条
- 任何项目先预检再购买流量,避免「超量补单」产生 20% 加急费。
- 含公式论文请勾选「保留公式为图片」,否则公式源码被拆散会导致字数虚增。
- 扫描件先执行 OCR→校对→再预检,可把误差压到 1% 以内。
- 使用企业术语库时,先锁定 100% 匹配再刷新字数,预算一目了然。
- 每月首日导出「字数报告 CSV」与财务对账,防止流量包到期清零造成浪费。
版本差异与迁移建议
v11.4 及更早版本无「刷新字数」按钮,若项目需锁定匹配,请升级至 11.5.0+;Mac 版 11.5.0 曾出现 OCR 进程卡死,官方已在 11.5.1 修复,建议自动更新通道保持开启。
未来趋势
官方 roadmap 提及 2026 Q2 将上线「按段计费」模式,系统会在预检阶段同步给出「重复段」「术语匹配段」「新译段」三项明细,字数统计颗粒度从「整篇」细化到「句段」,对大型翻译公司意味着更精确的 CAT 折让。若你所在团队月翻译量≥50 万字,可提前申请内测,现阶段只需在「设置-实验室」勾选「加入体验计划」即可排队。
收尾:一句话记住
上传前点「预检」,锁术语后「刷新」,有道翻译专业版的字数统计就能在预算、排期、合规三条线上一次对齐,省去事后对账 90% 的返工。
常见问题
预检结果与 Word 相差超过 1%,该信哪个?
以有道预检为准。后续流量计费、术语锁定均使用该引擎结果;若差异巨大,请检查是否启用了「排除页眉页脚」或「LaTeX 解析为文本」等选项。
扫描版 PDF 预检字数偏低怎么办?
先在「OCR 语言」下拉补选对应语种,再重新预检;若仍偏低,可导出 OCR 文本手动校对后,用 TXT 格式重新上传获取准确计数。
能否关闭「排除页眉页脚」功能?
目前该规则硬编码在引擎内,不提供开关;如页眉页脚含关键术语,建议将内容移至正文区域再上传。
刷新字数按钮灰色无法点击?
仅网页端与企业版客户端支持「刷新字数」;请先确认已导入术语库并勾选「锁定 100% 匹配」,若仍灰色,请升级至 11.5.0 以上版本。
📺 相关视频教程
Blox Fruits抽到好果怕被殺怎麼辦? #shorts